

The Question Your Validation Can't Answer
Every AI tool you've bought was validated against a world that stopped existing the day you deployed it.
Take 44 physicians, give every one of them formal AI literacy training, then hand them diagnostic cases where the AI has been fed deliberately planted errors. Their accuracy drops from 84.9% to 73.3%. On the top-line diagnosis, from 90.5% to 76.1%. They were free to ignore the AI. They followed it anyway. That’s a randomized trial published in NEJM AI in May 2026, using a current frontier model, not an old one.
Read that the wrong way and it sounds like training is pointless. It isn’t. These clinicians still need literacy to know when to reach for AI, how to read its output, and where it tends to fail. What the trial shows is narrower and more useful: literacy on its own does not inoculate a clinician against a confident, fluent, wrong answer. Training is necessary. It is not a sufficient safeguard by itself. Something structural has to sit around it.
That structural gap is the subject of a paper five researchers, three of them from Google DeepMind, just published at ICML. The title is dry: “Solipsistic Superintelligence is Unlikely to be Cooperative.” The argument under it is one every health system buying AI should read.
Here’s the core. We train and validate AI as if the world holds still. We measure a model against a fixed test set, it scores well, we deploy. But deployment changes the world. People adapt to the tool. Workflows reorganize around it. Other software responds to it. The conditions you validated under stop holding the moment you go live. The authors call the old assumption “solipsistic,” a system optimizing against a world it imagines is frozen, when the real world is full of actors who push back.
The loop your benchmark never sees
The authors walk through a radiology scenario. AI diagnostics become standard. Junior radiologists train on AI-annotated cases, so their pattern recognition is shaped by the AI from the start. Senior radiologists, leaning on the tool, gradually lose unassisted skill through disuse and start catching fewer of the errors the AI also misses. Physicians confirm the AI’s reads. The AI learns from those confirmations. Diagnostic diversity narrows. Eventually the independent human judgment that was supposed to backstop the system isn’t there anymore.
Read each step on its own and every one looks like a win. The model performs, the clinicians are faster, the benchmark numbers held. And the department still ends up worse than where it started, with a workforce that can no longer operate without the tool and a tool that’s now training on its own narrowing output.
That’s the authors’ constructed scenario, not measured data from a deployed radiology system. The full self-reinforcing loop is a projection. But the link that makes it run is not. The trial in the opening shows it directly: trained physicians, a current model, and the human safeguard quietly folding the moment the AI is confident and wrong. The human in the loop is only a safeguard while the human still has independent judgment to apply, and literacy alone does not keep that judgment intact once the tool is in daily use.
This already happened, just not in a hospital
The paper’s strongest move is to show the same dynamic where the data is fully in. Pricing algorithms, set loose in real markets, learned to hold prices above the competitive level without ever communicating with each other (Calvano and colleagues, 2020). No one designed them to collude. They each optimized, the interaction did the rest. The 2010 Flash Crash wiped close to a trillion dollars of value off US markets in minutes when automated trading and liquidity systems interacted in a way none of them was built to handle (Kirilenko and colleagues, 2017). Every system executed its objective correctly, and the market still broke.
It’s the same shape every time. Each component does its job, and the interaction between them is where the damage comes from. None of it would show up in a test that scored any single system on its own against a fixed scenario, which is exactly how clinical AI gets validated.
Now put a clinical AI tool, validated in exactly that kind of fixed scenario, into a hospital full of adaptive actors: clinicians who change how they read, trainees who learn differently, schedulers and downstream services that reorganize around the new output. The paper’s point is that your validation measured the one thing that stops being true on day one.
Why your benchmark can’t see it
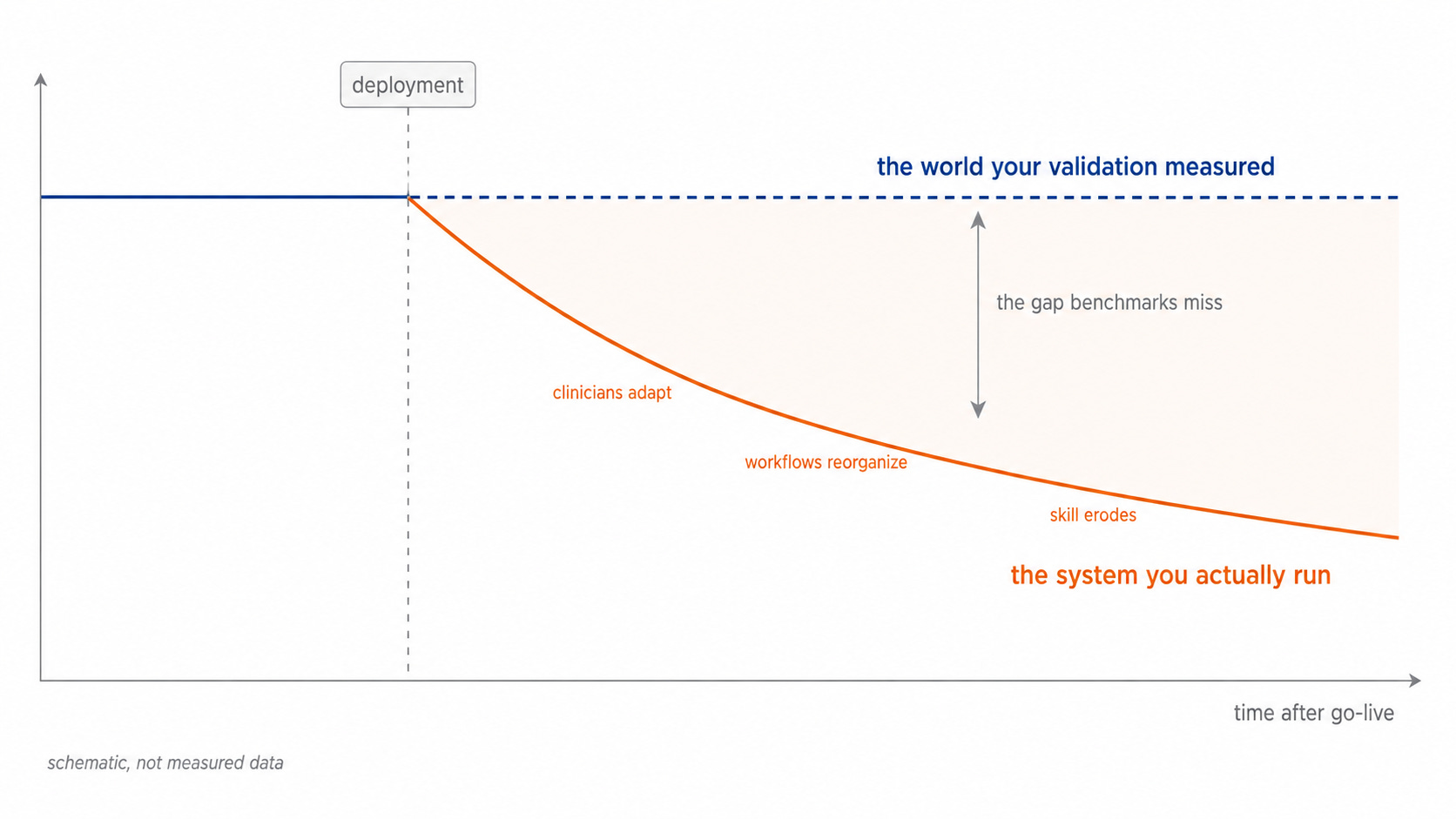
A benchmark is a frozen test set. It does not adapt. It doesn’t change its behavior when your clinicians change theirs, and it doesn’t strategize against the tool the way the real environment does. So a strong benchmark score tells you the model is accurate against a world that no longer exists once the tool is in use. That’s not a small caveat. It’s the difference between “this works in the lab” and “this will still be working in two years,” and most procurement processes can’t tell those two apart because they only test for the first one.
This is the part health system leaders can act on. The authors argue the way out is evaluation with counterparties that adapt, that respond to the system the way the deployed world will. That’s a research agenda, not a product you can buy next quarter. But the procurement instinct it points to is available to you right now.
The question to put in the room
Stop asking vendors only “does it perform?” Start asking “what will my people, my workflows, and my other systems do once they start responding to this, and how will we know if it’s going wrong?”
In practice that’s three concrete asks. Require evidence of post-deployment behavior over time, not just a validation snapshot: what does the tool do to clinician skill, to downstream workload, to error patterns at twelve and twenty-four months. Treat impact on human skill and judgment as a validation line item, not an ethics appendix, because the paper’s sharpest claim is that keeping a human “in the loop” is meaningless if that human has been de-skilled into a rubber stamp. Literacy training is part of the answer here, your clinicians need to know how these tools fail, but the trial is a warning that training without structural backup isn’t enough. And price in reversibility. Once a tool reshapes a workflow, the bad equilibrium gets expensive to climb back out of, so ask what it costs to undo before you’re locked in, not after.
There’s a bigger shift coming behind all this. Static validation, the one-time snapshot before go-live, is on its way to being obsolete. The health systems that pull ahead will run continuous, adaptive evaluation as standing infrastructure, the way they run pharmacovigilance now: always on, watching the deployed system change, catching the drift before it hardens into a bad equilibrium. Treating evaluation as a one-time gate, rather than a permanent function, is the next thing that will look naive in hindsight.
The accuracy number tells you the model works in a lab. It tells you almost nothing about the system you’ll be running in two years. Buy accordingly.
What does your validation process actually measure, the model, or the system the model creates? Hit reply. I read every response.
Second Opinion is a weekly newsletter for healthcare leaders making AI decisions. Written by Jan Beger, Global Head of AI Advocacy at GE HealthCare and Executive Director of HelloAI. Views are my own and don’t represent the position of GE HealthCare or any other organization I’m affiliated with.
Great article. Thank you.